-
-
学生向け無料ソフトウェアにアクセス
Ansysは次世代の技術者を支援します
学生は、世界クラスのシミュレーションソフトウェアに無料でアクセスできます。
-
今すぐAnsysに接続!
未来をデザインする
Ansysに接続して、シミュレーションが次のブレークスルーにどのように貢献できるかを確認してください。
無料トライアル
製品およびサービス
リソースとトレーニング
当社について
Back
製品およびサービス
ANSYS BLOG
June 30, 2022
Ansys FluentのためにGPUのフルパワーを解き放つ(パート2)
それぞれのタスクにかかる時間を数分、数時間、さらに数日節約できるとしたら、年間を通してどれだけの時間を節約できるか想像してみてください。そのタスクが数値流体力学(CFD: Computational Fluid Dynamics)シミュレーションであり、解析時間を節約したいのなら、Ansys FluentのGPUソルバーがソリューションを提供できるかもしれません。
解析対象が100,000セルのモデルであろうと1億セルのモデルであろうと、シミュレーション時間を短縮するための従来のアプローチは多数のCPUでの解析によるものです。近年注目を集めてきたもう1つのアプローチは、グラフィックスプロセッシングユニット(GPU: Graphics Processing Unit)を使用することです。これが始まったのは、全体的な解析時間を加速するためにCPUソリューションの一部がGPUに渡されたときであり、このことはGPUへのオフロードとして知られています。
当社がこのオフロード技術をAnsys Fluentに実装したのは2014年に遡りますが、今年、ネイティブのマルチGPUソルバーをFluentに導入することにより、当社はGPU技術の使用を全く新しいレベルに引き上げようとしています。ネイティブの実装により、すべてのソルバー機能がGPU上で提供され、CPUとGPUの間のデータ交換によるオーバーヘッドを回避できます。その結果、オフロードと比較するとさらなるスピードアップとなります。
CFDのためにGPUの全潜在能力を解き放つには、コード全体をGPUに常駐で実行する必要があります。
このブログシリーズのパート1では、大規模な自動車の外部空力シミュレーションが32倍にスピードアップすることに焦点を当てましたが、すべてのユーザーがそのサイズのモデルをシミュレーションしているわけではないことを、私たちは理解しています。このブログでは、多孔質媒体や共役熱伝達(CHT: Conjugate Heat Transfer)など追加の物理機能を含む、より小さいモデルに対するGPUのパワーに焦点を当てます。
あらゆるサイズのCFDシミュレーションのスピードアップ
512,000セルから700万超まで、このブログで説明するモデルはすべて、GPUで解析した場合に著しいパフォーマンスの向上を示しています。また、著しいパフォーマンス向上を実現するために、最も高価なサーバーレベルのGPUは必要ありません。FluentのGPUソルバーは、お手持ちのラップトップやワークステーションのGPUを使用して解析時間を大幅に短縮できるからです。でも、私たちの言葉をそのまま信用しないでください。読み続けて、ネイティブのマルチGPUソルバーがいかにして次のようなスピードアップをもたらしたかを確認してください。
- 吸気システムで8.32倍
- トラクションインバータで8.6倍
- 2つの異なる熱交換器の設計で15.47倍と11倍
多孔質フィルターを通る空気流
自動車の吸気システムは、空気を吸い込み、フィルターを通過させてデブリを除去し、清浄な空気をエンジンに送るために使用されます。この710万セルのシミュレーションでは、フィルターは、粘性抵抗1e+8m-2、慣性抵抗2,500m-1の多孔質媒体としてモデル化されています。空気は、質量流量0.08kg/sで吸気システムに流入しています。
1つのNVIDIA A100 GPUで解析したときに8.32倍にスピードアップされた、吸気システムを通る流線
このモデルを解析するために、4つの異なるハードウェア構成が使用されました。3つはIntel® Xeon® Gold 6242のコアで構成されており、残りの1つは、1つのNVIDIA A100 Tensor Core GPUで構成されています。
単一のNVIDIA A100 GPUを使用した結果、32コアのIntel® Xeon® Goldで解析した場合と比較して8.3倍スピードアップしました。
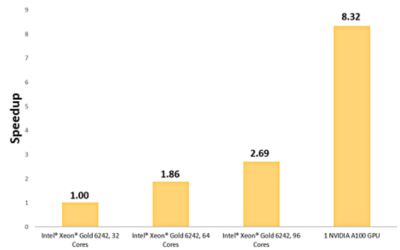
単一のNVIDIA A100 GPUを使用して多孔質媒体を通る空気流をシミュレーションした結果、32コアのIntel® Xeon® Goldと比較して8.3倍のスピードアップ
CHTモデリングを使用した熱マネジメント
多くの産業用途では、流体流れと共に熱の効果を考慮することが重要です。システムの熱的挙動を正確に捉えるために、流体内の熱伝達を隣接する金属の熱伝導と連成することが、しばしば重要となります。当社のネイティブのGPUソルバーは、これらの連成CHT問題に関して大幅なスピードアップを示します。
CHTを含む3つの異なる伝熱シミュレーション(400万セルの水冷トラクションインバータ、140万セルのルーバーフィン熱交換器、512,000セルの縦置きのヒートシンク)を以下に示します。
水冷トラクションインバータ
1つのNVIDIA A100 GPUで解析したときに8.6倍にスピードアップされた、CHTを含むトラクションインバータのシミュレーション
トラクションインバータは、高圧バッテリーから直流を取り込み、それを交流(AC)に変換して電動モータに送ります。安全性と長寿命の両方を確実にするために、トラクションインバータにとって熱マネジメントは重要です。
上に示したモデルは、400万セルの水冷トラクションインバータであり、熱負荷が400Wの絶縁ゲートバイポーラトランジスタ(IGBT: Insulated Gate Bipolar Transistor)を4つ備えています。冷却には、0.5kg/sでハウジング内を循環する25°Cの水を使用し、周囲空気への熱排出は対流境界条件を使用してモデル化されています。
1つのNVIDIA A100 GPUで解析した結果、32コアのIntel® Xeon ® Gold 6242と比較して8.6倍のスピードアップとなりました。
ルーバーフィン熱交換器

この熱交換器モデルでは、ルーバーフィン熱交換器を通る強制対流を使用します。この問題は、4m/sの速度でアルミニウムのルーバーフィンを通って銅チューブを冷却する20°Cの空気で構成されています。
ベースラインを確立するために、140万セルのモデルを8コアのIntel® Xeon® Gold 6242で実行しました。この全く同じモデルを1つのNVIDIA A100 GPUで実行した結果、15.5倍のスピードアップとなりました。
1つのNVIDIA A100で15.47倍速く解析されたルーバーフィン熱交換器の温度コンター
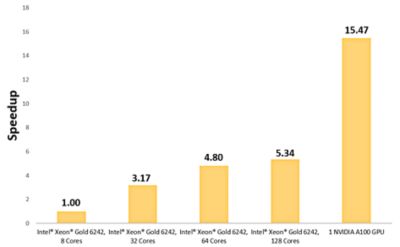
ルーバーフィン熱交換器に関して単一のGPUがシミュレーション解析を15.47倍スピードアップ
縦置きのヒートシンク
最後の問題は、底部が76.85°Cの一定温度に、周囲空気が16.85°Cの周辺温度に保たれている、自由対流の5フィンのアルミニウムヒートシンクで構成されています。
この512,000セルのケースを、1つのNVIDIA Quadro RTX 5000 GPUを搭載したラップトップで解析した結果、6コアのIntel® Core™ i7-11850Hが搭載されたラップトップと比較して11倍のスピードアップとなりました。
NVIDIA Quadro RTX 5000のような単一のラップトップGPUを使用している場合であっても、Fluentに含まれるネイティブのマルチGPUソルバーにより、解析時間の大幅な短縮が期待できます。同様のグラフィックスカードをワークステーションで使用すれば、さらに高いパフォーマンスが期待できます。
512,000セルのヒートシンクのシミュレーションを1つのNVIDIA Quadro RTX 5000 GPUで解析したところ、11倍にスピードアップ。
GPUによるCFDシミュレーションの大変革
単一のGPUを搭載したラップトップまたはワークステーション上で実行したり、マルチGPUサーバーにスケールアップしたりするパワーと柔軟性がFluentに備わりました。すでに所有しているハードウェアを活用して、今まで可能と思っていたレベルを超えて、CFDシミュレーションをスピードアップしてください。
Fluentに含まれるネイティブのマルチGPUソルバーは、CUDAドライバー11.0以降がインストールされている2016年以降のNVIDIAカード上で動作します。
Ansysは、シミュレーションへのGPU技術の使用における先駆者であり続けており、この新しいソルバー技術により、これを全く新しいレベルに引き上げようとしています。ネイティブのGPUソルバーに含まれるソルバー機能はすべて、FluentのCPUソルバーと同じ離散化方法と数値解析法で構築されており、ユーザーが期待する正確な結果を、これまでになく短時間で提供します。