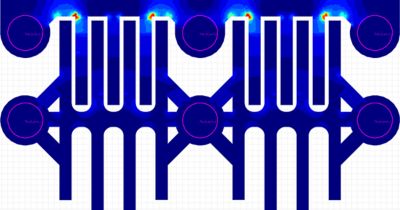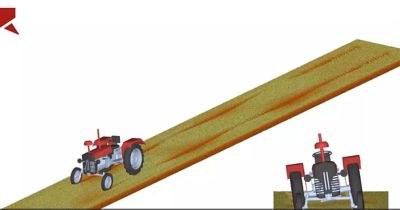


















The Ansys Advantage Blog
The Ansys Advantage blog, featuring contributions from Ansys and other technology experts, keeps you updated on how Ansys simulation is powering innovation that drives human advancement.
All Ansys
Products
Resource Center
News
Events
Partners
Blog
Education Resources
Customer Spotlights