Synopsys and Ansys power the future of innovation—connecting silicon to systems.
-
-
Access Free Student Software
Ansys empowers the next generation of engineers
Students get free access to world-class simulation software.
-
Connect with Ansys Now!
Design your future
Connect with Ansys to explore how simulation can power your next breakthrough.
Free Trials
Products & Services
Learn
About
Back
Products & Services
Back
Learn
Ansys empowers the next generation of engineers
Students get free access to world-class simulation software.
Back
About
Design your future
Connect with Ansys to explore how simulation can power your next breakthrough.
Free Trials
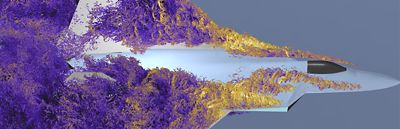
We have reached a new era in computational fluid dynamics (CFD) — one in which we no longer need to wait tremendous amounts of time for high-fidelity, scale-resolved simulation results. Waiting weeks or months is a thing of the past, and just ahead is an exciting future in which simulations can be completed within a single working day while still maintaining predictive accuracy. This is going to change how industries use CFD and will create ripple effects far beyond the simulation field.
Enabling the Next Generation of CFD With GPUs
Graphics processing units (GPUs) are fundamentally different than central processing units (CPUs). GPUs have a higher density of arithmetic logic units (ALUs), require lower energy to execute instructions, and have higher-memory bandwidth. Essentially, this means that you have significantly more computational horsepower at iso-hardware costs or iso-energy consumption.
The simulation market is adopting GPU technology, including Ansys Fluent fluid simulation software, to take advantage of the superior performance capabilities of GPUs. By running CFD simulations on GPU hardware, users can run more designs under more conditions in less time. Ultimately, this leads to creating more reliable products with fewer field failures at greater efficiency and sustainability.
A great example is the recent work that Ansys performed with NVIDIA and the Texas Advanced Computing Center (TACC). The partnership was created to run the DrivAer automotive benchmark model on a 2.4 billion-cell mesh. When running on 320 Grace Hopper superchips, Fluent software produced a staggering 110X speedup relative to the same model running on 2,000 CPU cores. Those 320 GPUs gave the incredible performance equivalent of more than 225,000 CPU cores. This breakthrough cut simulation time from nearly a month to just over six hours.
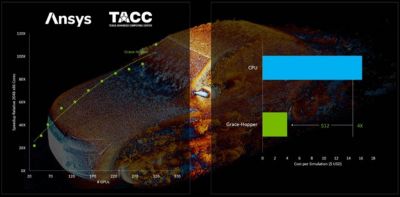
An automotive benchmark of a 2.4 billion-cell DrivAer dataset run on the Vista System at TACC with NVIDIA Grace Hopper GPUs
Of course, not everyone has access to NVIDIA Grace Hopper chips or TACC’s supercomputer. Still, you can see incredible simulation runtime improvements with more accessible GPU card options.
For example, using the same case as above with a smaller quarter-of-a-billion-cell mesh count, we reduced the simulation runtime from 52 hours (on 512 cores) to just 40 minutes on 64 NVIDIA L40 GPUs. NVIDIA L40 GPU cards are readily available and can be very cost-effective for some businesses, especially when considering the savings that can also be incurred from energy and electricity savings.
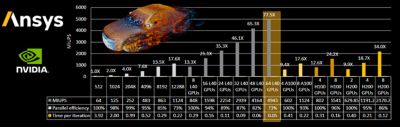
A 250 million-cell cell transient, scale-resolved case solved in just 40 minutes on 64 NVIDIA L40 GPUs
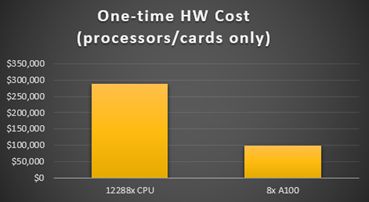
A one-time purchase of eight NVIDIA A100s is about three times cheaper than purchasing the equivalent CPU cores necessary to run the model in the same amount of time.
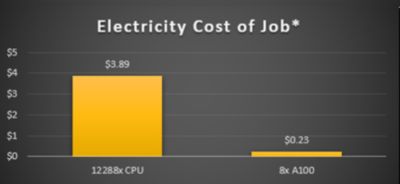
Electricity costs are also significantly lower when running a job on eight NVIDIA A100s than the equivalent 12,000-plus CPU cores. (Electricity cost is estimated at about 0.13/kWh.)
Beyond just a pure performance benefit, GPU cards can also be more cost-effective from a purchasing and energy standpoint than CPUs. As shown above, the cost to run the same case as shown above on 12,288 CPU cores (the cores necessary to run in the same amount of time as 8 NVIDIA A100s) was around 3X more expensive. And when looking at the electricity cost of the job, the costs associated with running on CPUs are significantly more expensive than running on 8 NVIDIA A100 GPU cards.
Leveraging GPU hardware, even if it is not top of the line, can still result in some amazing benefits, not only for simulation solve time improvements but also hardware and energy savings.
Access the Ansys Fluent GPU Hardware Buying Guide to learn more.
Achieve Faster Preprocessing With Rapid Octree Meshing
Solving is just one portion of a simulation workflow, though often the most time-consuming. While we dramatically reduce solve times thanks to GPUs, the time spent preprocessing and meshing large, complex models is becoming increasingly substantial for models that require high levels of detail.
Fluent software offers a compelling solution with the rapid octree meshing method. Rapid octree meshing is a top-down meshing approach that is less sensitive to imperfections in the input computer-aided design (CAD) file than traditional, bottom-up meshing approaches. This enables a highly automated and scalable meshing preprocessing with minimal manual interaction while ensuring the geometry is still accurately represented.
As shown in the accompanying graph, as the number of cores increases, the meshing efficiency in terms of millions of cells per minute increases. Starting at 1,320 cores, the mesh for a complex nonreactive geometry is completed at 41.5 million cells per minute. At 3,960 cores, that number increases to 124 million cells per minute, giving a 99% scaling efficiency. This gives an overall meshing time of 30 minutes on 3,960 cores for a 3.7 billion-cell mesh.
Combining rapid octree meshing technology with our extremely fast GPU solver massively reduces the time to solution from end to end, enabling shorter design cycles, increased design exploration, and ultimately faster time to market.
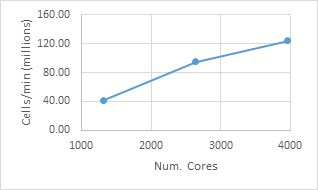
Rapid octree mesh scalability for a 3.7 billion-cell mesh
Real-World Examples: Meshing and Solving in One or Two Working Days
1 Billion-Cell Combustor Simulation Solved in Just 28 Hours
In 2025 R1, Ansys introduced the flamelet-generated manifold (FGM) model into the Fluent GPU solver. This meant that engineers working on gas turbine combustion could now leverage the associated speedups for their simulations.
In the use case below, an efficient energy engine (EEE) full annular combustor was processed in just 16 minutes using rapid octree meshing technology on 1,536 CPU cores. The case was then run on the Fluent GPU solver using the FGM model with reacting flow and spray in 28 hours on 48 NVIDIA L40s.
A 1 billion-cell EEE full annular combustor was meshed in 28 minutes and solved in 28 hours on 48 NVIDIA L40 GPUs.
What was once a “hero” calculation — one that takes massive computational resources and weeks or months to solve — is now becoming much more commonplace. By combining scalable meshing and GPU hardware, we are witnessing a step-change in CFD use across industries.
1 Billion-Cell Aircraft External Aerodynamics Simulation Solved in 30 Hours
Simulating external aerodynamics can be quite complex, requiring scale-resolving simulations (SRS) to accurately predict the acting forces. To achieve the required accuracy, cell counts must increase to capture the development and dissipation of turbulent structures. By using smaller cells to better resolve the surfaces and turbulence effects, the required time step size reduces, too. This leads to a substantial consumption of computational resources to improve designs even further.
With the Fluent GPU solver and rapid octree meshing method, the 1 billion-cell large eddy simulation (LES) of a high-lift aircraft was run in just 30 hours on 40 NVIDIA L40 GPUs. The mesh was generated in just 28 minutes on 512 CPU cores.
A 1 billion-cell LES of a high-lift aircraft solved in just 30 hours on 40 NVIDIA L40 GPUs
600 Million-Cell Jet External Aerodynamics Simulation Solved in 14 Hours
An external aerodynamic simulation of a fifth-generation jet was solved on 600 million cells in just 14 hours—an incredible solve time, considering the level of detail included in the simulation. The jet was meshed in 30 minutes using rapid octree meshing on 480 CPU cores and solved in just 14 hours on 20 NVIDIA L40 GPU cards using wall function LES.
A 0.6 billion-cell external aerodynamics simulation solved in just 14 hours on 20 NVIDIA L40 GPU cards
Customer Success Stories
Outside our internal benchmarking, customers who have adopted both rapid octree meshing and the Fluent GPU solver technology have seen great performance benefits resulting in massive time savings for their CFD simulations.
Baker Hughes
In April, Ansys, Baker Hughes, and the Oak Ridge National Laboratory set a supercomputing record on AMD Instinct GPUs, reducing simulation runtimes by 96% for a 2.2 billion-cell axial turbine simulation.
Compared to methods that utilize over 3,700 CPU cores, Baker Hughes and Ansys reduced the overall simulation runtime from 38.5 hours to just 1.5 hours using 1,024 AMD Instinct MI250X GPUs. This record-breaking scaling means faster design iterations and more accurate predictions, ultimately unlocking more sustainable technologies and products.
Volvo
In March 2025, Volvo announced that they reduced their total vehicle external aerodynamic simulations from 24 hours to just 6.5 hours using rapid octree meshing on CPUs and the Fluent GPU solver on 8 NVIDIA Blackwell GPUs — setting a benchmark in the automotive industry and beyond.
Leonardo Helicopters
Last year, Leonardo Helicopters adopted Fluent GPU solver technology to simulate the aerodynamics of helicopter rotors using LES. They not only saw a 2.5X reduction in their simulation runtimes but also an 80% reduction in energy use from 85 kWh to 15 kWh.
Seagate
In 2024, Seagate, a mass-capacity data storage company, utilized the Fluent GPU solver and NVIDIA GPU hardware to speed up the runtimes of their internal drive flow models. They saw a staggering 50X runtime improvement, with runtimes reduced from one month to less than one day.
Harnessing the Power of GPUs for Future Innovation
Ultimately, it’s widely known that simulation reduces design cycles and saves costs. The adoption of GPU hardware technology will help reduce these design cycles even further — from weeks or months to days, hours, or even minutes. A future in which simulations across all physics can be performed that fast is nearly here.
Discover how the Ansys Fluent GPU solver can speed up your simulations at the links below.
Learn More



The Advantage Blog
The Ansys Advantage blog, featuring contributions from Ansys and other technology experts, keeps you updated on how Ansys simulation is powering innovation that drives human advancement.