ANSYS BLOG
February 8, 2023
Simulating Reality: The Importance of Synthetic Data in AI/ML Systems for Radar Applications
Artificial intelligence and machine learning (AI/ML) are driving the development of next-generation radar perception. However, these AI/ML-based perception models require enough data to learn patterns and relationships to make accurate predictions on new, unseen data and scenarios.
In the field of radar applications, the data used to train these models is often collected from real-world measurements, which can limit the quality, quantity, and coverage of the data. Synthetic data offers the potential to overcome these limitations by augmenting or replacing real-world data with artificially generated data that mimics the behavior of real-world systems.
Simulation is one of the strongest tools in collecting synthetic data. In addition to its ability to virtually replicate and test countless conditions, simulation can generate large quantities of synthetic data that cover a wide range of scenarios, including instances that are rare, difficult, or dangerous to observe in the real world. This can help improve the performance and generalizability of AI/ML-based radar perception models by informing the data with more specific and unique circumstances.
Ansys has developed an efficient simulation workflow to model complex radar scenarios in real time using an electromagnetic simulation technique based on the shooting and bouncing rays (SBR) method. This solver is based on the same SBR solver found within Ansys HFSS and has been graphics processing (GPU)-unit accelerated to perform simulation in real time. This radar sensor simulation capability is available within Ansys AVxcelerate Sensors add-ons. We will explore Ansys’ radar sensor capabilities and related use cases in the next blog of this series, but first, let’s dive deeper into the importance of synthetic data in radar applications.
Synthetic Data: Overcoming Challenges, Fast
For the purposes of training and testing AI/ML models, synthetic data has many potential benefits over physical data. Firstly, you need to label and sanitize real-world data before use but this is inherent with synthetic data and simulation. To build a simulation model you select which components to include and where to place them. This means that you are in control of the environment and, essentially, you are choosing and creating the ground truth of the study. As a result, by using simulation, the labels needed for AI/ML training are highly accurate. Similarly, you can use synthetic data to effectively train deep learning processes and neural networks (NN).
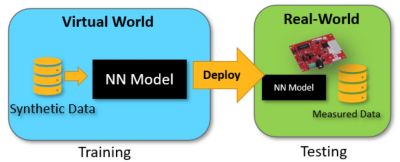
Figure 1: Synthetic data can be used to train artificial intelligence/machine learning (AI/ML) models, including deep learning processes and neural networks (NN).
Additionally, corner case testing — testing multiple parameters for extreme levels from the corner of a configuration space — is very difficult, if not impossible, in the real world. Historically, AI/ML algorithms are not equipped with enough real-world testing data to accurately train models for such corner cases and fail by consequence. However, with simulation you can easily recreate dangerous or rarely occurring situations to fill the gaps of physical testing. In this way, synthetic data both complements and augments real-world testing by increasing sample size and providing unique training opportunities that are not possible with real-world data alone.
Speed and efficiency are two other top benefits of using synthetic data. Existing solutions typically depend on real-world measured data. This can be expensive, inefficient, time-consuming, and even impossible to collect because the range of scenarios needed for training and testing may not even exist.
Synthetic Data in Autonomous Vehicles and Other Applications
Consider the amount of time, distance, and exertion it would require to physically test and verify the safety and reliability of autonomous vehicles. The number of variables from driving conditions to roadways are nearly limitless. Simulation offers a major advantage here by not only making it possible to virtually test countless conditions but by generating enough synthetic data to complement and maximize physical data.
Figure 2. This video demonstrates how machine-learning-based radar perception and simulation are used to assess scenarios for autonomous vehicles. Simulation results are shown in the picture-in-picture image at the top right of the video.
This is especially helpful when assessing dangerous and complex situations that may be too difficult or impossible to acquire real world measurements.
Synthetic data has proven to be an effective tool in a variety of applications. One such example uses synthetic data to detect, classify, and locate targets utilizing Range-Doppler maps1, as depicted in Figure 2. This showcases how the integration of ML and physics-based simulations can enhance the safety of autonomous vehicles.
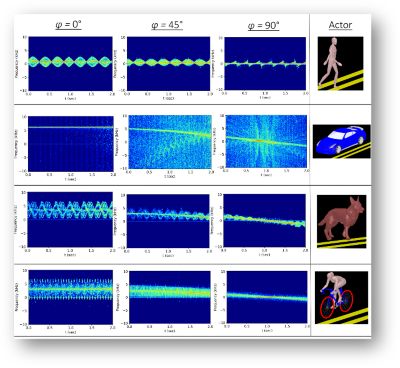
Figure 3. Synthetic data and physics-based simulations can be used to train convolutional neural networks (CNN).
Another application example, illustrated in Figure 3, demonstrates how physics-based simulations can be used to train a convolutional neural network (CNN) to identify whether a target is a person, car, biker, or dog, by analyzing the micro-Doppler effects captured in a Doppler spectrogram2.
A final example, shown in Figure 4, highlights the use of synthetic data as it is applied to reinforcement learning. Ansys’ webinar series: Reinforcement Learning with Physics-based Real Time Radar for Longitudinal Vehicle Control, demonstrates a vehicle’s real-time training and progress as it learns to control its speed and braking within realistic scenarios.
Figure 4. This video illustrates reinforcement learning using physics-based simulation for vehicle controls.
Industries outside the automotive market are also developing a wide-range of radar applications, including:
- In-room monitoring of consumer electronics: smart devices that detect when you are in the room and what you are doing.
- Security applications: systems that detect how many people are at a location and whether the people are moving or not.
- Health monitoring: monitors that track your vital signs without being attached to you.
Real-Time Radar Game Changer, Stay Tuned
Synthetic data contributes an abundance to AI/ML training and the AVxcelerate GPU-accelerated SBR solver makes synthetic data generation easier, more reliable, and accurate. Additionally, Ansys’ simulation enables large-scale synthetic data generation, which is required to thoroughly train AI/ML models for wide-ranging circumstances.
It is equally important to create true-to-life datasets quickly. Ansys’ radar sensor simulation capabilities achieve this by incorporating SBR techniques that combine both geometric and physical optics with EM waves.
Stay tuned for the next blog in this series to learn more about Ansys’ radar sensor simulation solutions through use cases that demonstrate how synthetic data is used to train ML models and test performance on real-world data.
Learn More
- Ansys AVxcelerate realistic sensor testing and validation enables you to test your autonomous vehicles, ADAS and sensors faster than with physical prototypes.
- Discover how visionary companies are leveraging the power of artificial intelligence (AI), machine learning (ML), deep learning (DL), and simulation to take a leap of certainty when solving complex engineering problems.