Synopsys and Ansys power the future of innovation—connecting silicon to systems.
-
-
学生向け無料ソフトウェアにアクセス
Ansysは次世代の技術者を支援します
学生は、世界クラスのシミュレーションソフトウェアに無料でアクセスできます。
-
今すぐAnsysに接続!
未来をデザインする
Ansysに接続して、シミュレーションが次のブレークスルーにどのように貢献できるかを確認してください。
無料トライアル
製品およびサービス
リソースとトレーニング
当社について
Back
製品およびサービス

Ansysは、Gefionスーパーコンピュータ上でNVIDIA CUDA-Qを活用することで、数値流体力学シミュレーションを39量子ビットまでスケールアップすることに成功しました。
数値流体力学(CFD)シミュレーションは、航空宇宙、自動車、エネルギー、プロセスなどの業界で不可欠なツールとなっています。設計サイクルの加速と精度要件の高まりに伴い、CFDモデルの規模と複雑さは増大し続けており、メモリ容量の増加、空間解像度の向上、計算時間の短縮に対するニーズが高まっています。Ansysは長年にわたり、これらの課題に対応する取り組みをリードし、高性能ソルバーの開発を先導するとともに、ハイパフォーマンスコンピューティング(HPC)と人工知能(AI)を統合することで、精度を損なうことなく収束を加速し、計算コストの削減を実現してきました。
AnsysのCTOオフィスでは当初、研究コミュニティによる確立されたベンチマークを活用して、CFD分野に注力していましたが、現在は偏微分方程式(PDE)の高速化を目的とした量子アルゴリズムの研究を積極的に推進しています。私たちは、NVIDIA CUDA-Qオープンソース量子開発プラットフォームを採用して、量子アプリケーションスタックを構築しています。これにより、ノイズのない環境でスケーラブルなGPUベースのアルゴリズムシミュレーションが実行できるようになるだけでなく、ノイズ中間スケール量子(NISQ)時代を超えて、量子ハードウェアでシームレスに実行することも可能になります。産業レベルの規模と複雑さに対応できるアルゴリズムを特定した後は、次の研究ステップとして、ハードウェア上での実証実験に進む予定です。この反復プロセスにより、量子対応に向けて、最も効果的な方法に収束させることができます。
ハイブリッド量子-古典ワークフローの開発と、GPUによって高速化された量子回路シミュレーションで柔軟性を発揮するNVIDIA CUDA-Qプラットフォームは、私たちが探求しているアルゴリズムのスケーラビリティを研究する上で重要な役割を果たしてきました。
量子コンピューティングとCFDの融合
量子アルゴリズムは、情報を量子システムに符号化して処理する斬新な方法を巧みに活用しようとするものです。量子システムは、計算負荷の高いCFDシミュレーションにおいては特にメリットが大きく、以下の点で期待されています。
高次元:古典的なビットとは異なり、量子ビットは、その数に応じて指数関数的にデータ量を拡張でき、量子ビットの追加ごとに、処理できるデータ空間が倍増します。量子コンピューティングでは、量子状態の振幅で計算グリッド全体(数十億個の点を含む可能性がある)を表現することで、非常に広大な解空間を活用することができます。実際、このブログの後半で示すように、私たちは680億のグリッド点を含む問題を39量子ビットのみで解くことができました。
並列的なグローバル更新:量子コンピューティングでは、CFDで一般的に用いられる時間ステップを通じてデータを反復的に更新する処理を、コヒーレントなグローバル操作として、1回の回路実行で実施できる可能性があります。これにより、反復的なカーネル呼び出しを行うのではなく、すべてのグリッド点を同時に更新できるようになります。
しかし、これらの特性を実用的なCFDに適用することは、前述の直感が示唆するものよりもはるかに複雑で繊細な作業です。この作業には、量子ビットに符号化されたCFD情報の操作だけでなく、その読み出しも可能にする、巧妙に構築されたアルゴリズムが必要です。これらの目標を達成する手段の1つとして、量子格子ボルツマン法(QLBM)が挙げられます。
量子格子ボルツマン法(QLBM)とは
CFDでは、スカラー密度場の輸送が移流拡散方程式によって支配されます。この方程式は、古典的な数値解析法を開発する際に初期ベンチマークとしてよく用いられる典型的な問題です。
QLBMは、古典的な格子ボルツマン法の量子ネイティブな実装であり、ここでは、量子ハードウェア上で流体の問題を効率的に解くために調整されています。QLBMは、局所的で構造化された固有の更新ルールを備えており、このルールを量子回路に自然にマッピングできるため、量子CFDに特に適しています。QLBMは、LBMのシンプルさとモジュール性を維持しながら、量子コンピューティングの指数関数的なデータ表現能力と処理能力を引き出すことができます。
QLBMの各時間ステップは、以下の4つの主要な操作で構成されます。
- 状態準備:離散格子上のスカラー密度場を符号化する振幅を持つ「グリッドレジスタ」を初期化します。
- 衝突:ユニタリーの線形結合によって、衝突操作を実行します。このステップには、グリッドレジスタ内のもの以外の補助量子ビットが必要です。
- ストリーミング:制御シフト演算子を実行することで、振幅を移流動力学に従って伝播させます。
- 読み出し:量子レジスタを測定して、密度分布を更新し、再構築します。
これらの操作を組み合わせてQLBMを使用することで、格子全体に対する時間ステップの更新を単一のコヒーレントな量子操作として実行できるようになり、古典的な陽的時間進行法でよく見られる点ごとの逐次更新が不要になります。
記録的規模の39量子ビットシミュレーション
AnsysはNVIDIA社との協業により、DCAI(デンマークAIイノベーションセンター )のGefionスーパーコンピュータ上の183個のノードでCUDA-Qを活用し、39量子ビットのQLBMシミュレーションの実行に成功しました。
- 36個の空間量子ビット:218×218の2Dグリッドを符号化しました(約680億自由度)。
- 3個の補助量子ビット:衝突およびストリーミングのロジック処理をサポートしました。
- プラットフォーム:CUDA-Qで作成されたアルゴリズムコードによって、CUDA-Qの「cpu」ターゲットを使用し、ローカルCPU上で小規模な初期テストを実施しました。その後、「nvidia」ターゲットを介してオンプレミスのGPUを使用することで、中規模なビルドアウトにスムーズにスケールアップすることができました。最後的には、CUDA-Qのターゲットを「mgpu」に変更するだけで、同じコードを使用したまま、Gefion上の183個のノード、合計1,464基のGPUを活用した大規模な処理を行うことができました。近い将来、CUDA-Qがサポートする量子ビットの種類に関係なく、同じコードを用いてQPUでの実行が可能になることが期待されています。
大規模なAI最適化インフラ
最先端の計算能力を提供し、さまざまな分野でAIの活用を加速させることを使命とするDCAIが運営するAIスーパーコンピュータ「Gefion」でシミュレーションを実行しました。GefionはNVIDIA社のDGX SuperPODアーキテクチャを基盤としており、世界で最も優れたスーパーコンピュータ500台をランク付けしたTOP500リストで21位にランクインしています。
Gefionの高度なコンピュートファブリックは、複数のサーバを1つのシステムとして機能させることで、各ノードに3.2Tbit/sの接続を提供します。これは、アルゴリズムが大規模な量子状態ベクトルを構築し、操作できるようにするのに役立ちました。また、CUDA-Qフレームワークのnvidia-mgpuターゲットを使用して、GPU VRAMをノード間でプールし、状態ベクトルを生成することで、メモリ管理の負担から解放されるようにしました。
シミュレーションのピーク時には、それぞれ8基のH100 GPUで構成された183個のDGXノード(合計1,464基のGPU)を使用し、約85.7 PFLOPS(FP64テンソル)を達成しました。コンピュートインターコネクトには、各GPUがコンピュートファブリックに400Gbit/sで直接接続された8レール構成の高速NVIDIA Quantum-2 InfiniBandネットワークが使用され、各GPU間で毎秒数十GBのデータが転送されます。ストレージシステムは800Gbit/sで接続されており、IO500ベンチマークにおいて200GB/sを超える帯域幅(563GB/sの「easy write」と910GB/sの「easy read」)を達成しています。
Gefionは、プロジェクト中の計算の並列化に最適なテストベッドとして機能し、解析コンポーネントをクラスタ全体にスムーズに分散させることができました。また、プロジェクトは、適応的なリソース割り当てモデルとHPCエキスパートによる運用チームにより、ハードウェアの性能を最大限に引き出す形でシームレスにスケールアップできました。
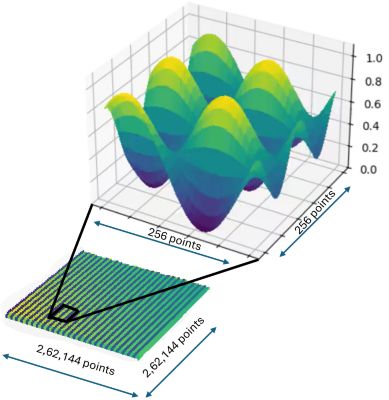
2,62,144×2,62,144グリッド上で39量子ビットを使用して、2次元正弦波の一様な移流-拡散現象をシミュレーションした。
Ansysは、ソルバー開発における独自の深い専門知識と、NVIDIA社の高性能CUDA-Qプラットフォームに関する先駆的な量子アルゴリズム研究を統合することで、量子加速流体力学のロバストな基盤を確立しました。量子コンピューティング技術が進展する中、この研究は重要な一歩として、産業規模の量子CFD開発への体系的な道筋を示し、将来のエンジニアリング課題で求められる計算需要の増大に対応します。
詳細については、『Algorithmic Advances Towards a Realizable Quantum Lattice Boltzmann Method(実現可能な量子格子ボルツマン法に向けたアルゴリズム的進展)』をご覧ください。




Advantageブログ
Ansys Advantageブログでは、専門家が投稿した記事を公開しています。Ansysのシミュレーションが未来のテクノロジーにつながるイノベーションをどのように推進しているかについて最新の情報をご覧ください。