Synopsys and Ansys power the future of innovation—connecting silicon to systems.
-
-
学生向け無料ソフトウェアにアクセス
Ansysは次世代の技術者を支援します
学生は、世界クラスのシミュレーションソフトウェアに無料でアクセスできます。
-
今すぐAnsysに接続!
未来をデザインする
Ansysに接続して、シミュレーションが次のブレークスルーにどのように貢献できるかを確認してください。
無料トライアル
製品およびサービス
リソースとトレーニング
当社について
Back
製品およびサービス

粒子状物質は、自動車、ヘルスケア、ハイテク、鉱業など、多くの業界で利用されています。こうしたバルク材料の動力学をモデル化することは、プロセスと設備性能の両面から、長年にわたり課題となってきました。
離散要素法(DEM)シミュレーションは数年前まで、数千個の大きな粒子(主に球形)のみを使用するような小規模な問題に限定されていました。数値解析法とハードウェア技術の進化により、意思決定に必要な忠実度の高い価値あるデータを提供できる精度レベルに達したのは、つい最近のことです。DEM手法の革新的なアルゴリズムと、グラフィックスプロセッシングユニット(GPU)の計算能力によって、新たな可能性が切り開かれました。
DEMコードと計算能力が継続的に改善されてきたことで、より現実に近い粒子シミュレーションを行うことが可能になりました。ユーザーは、リアルな粒子形状と実際の粒子径分布(PSD)を使用して問題をシミュレーションし、数百万個の粒子を含むDEMシミュレーションを作成することができます。
しかし、こうしたシミュレーション精度の向上には、処理時間とメモリ要件における計算負荷の増加という犠牲が伴います。
粒子動力学シミュレーションソフトウェアAnsys Rockyでは、GPUを活用することで、これらの負荷を軽減し、より実用的な時間枠で結果を得ることができます。
GPUの利点とその仕組み
GPUを導入したことで、DEMはエンジニアリング設計に有効なツールとなりました。これにより、RockyのGPUアクセラレーションソフトウェアコードなどでDEMの全機能を活用し、DEMシミュレーションモデルに含まれる数千万の粒子を処理できるようになりました。マルチGPU並列処理機能により、解析の適用範囲は大幅に拡大し、数億個の粒子を含む問題をDEMシミュレーションで解析することも可能になりました。
Ansysはマルチフィジックスシミュレーションをこれまで以上に推し進めています。RockyのGPUおよびマルチGPU処理を活用することで、すべてのCPUを連成シミュレーション用に活用し、ハードウェアの競合を回避することができます。
GPUは、DEMシミュレーションのスループットを大幅に向上させる可能性を秘めており、GPU上で動作するようにRockyのマルチGPUソルバーをネイティブ実装することで、当社はこの技術革新の最前線に立っています。
数百万個の粒子を含む大規模なDEMシミュレーションは、ハードウェアのメモリを大量に消費します。また、CPUメモリは高価であり、シミュレーションのパフォーマンスが大きく変動する可能性もあります。単一のCPUまたはGPUのメモリ容量には限りがあり、この容量によって、処理できる粒子数が制限されることもあります。
しかし、RockyのマルチGPUソルバーは、1つのマザーボード上で2つ以上のGPUのメモリを効率的に分散および管理することで、この制限を克服しています。たとえば、サイクロン分離器のシミュレーションでは、マルチGPUソルバー技術を使用したことで、2億個の粒子をシミュレーションすることができました。このような大量の粒子のシミュレーションはこれまでは不可能でしたが、現在では、RockyのマルチGPU機能によって実現可能となりました。

サイクロンシミュレーション(粒子数2億)
回転ミルの性能ベンチマークケース
一般的なケースにおける処理速度の向上と、ハイエンドGPUで実行する際のRockyソルバーのスケーラビリティをより適切に示すために、回転ミルのパフォーマンスベンチマークケースを開発しました。このケースは、一定速度で回転するドラム内に粒子が部分的に充填された状態で構成されています。シミュレーション開始時点では、すべての粒子がドラム内に存在し、定常状態にあります。
ベンチマークケースのパラメータ:
- ドラムの回転速度:1回転/秒
- シミュレーション時間:0.01秒
- 粒子数: 1,600万および3,200万
- 粒子タイプ:多面体(16個の三角形)

回転ミルの性能ベンチマークケース
ベンチマークに選ばれた粒子タイプは、16個の三角形の面を持つ多面体であり、実際の形状条件を適切に再現していました。
両方のケースで同じ配位数を維持するために、粒子数とミルの長さの比率と、接触数と粒子数の比率を同じに保つように考慮した結果、粒子数が増加するにつれて、回転軸方向のミルの長さが増加しました。
GPUの構成:
- NVIDIA H100 Tensor Core GPU 1基(合計メモリ94GB)
- NVIDIA H100 Tensor Core GPU 2基(合計メモリ188GB、NVLink)
- NVIDIA H100 Tensor Core GPU 4基(合計メモリ320GB、NVLink)
- NVIDIA H100 Tensor Core GPU 8基(合計メモリ640GB、NVLink)

16個の三角形の面を持つ多面体粒子

3,200万個の粒子に対して使用された回転ミルの長さは、1,600万個の粒子に対して使用されたものの2倍であった。
いずれのケースにおいても、RockyソルバーはマルチGPU実行により優れたスケーラビリティを発揮し、1,600万粒子では6.7倍、3,200万粒子では7.1倍の相対的な高速化を達成しました(NVIDIA H100 Tensor Core GPU 8基を使用した場合)。
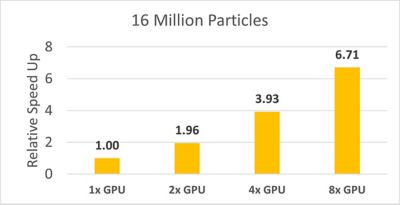
粒子数が1,600万個のケースでの相対的な高速化
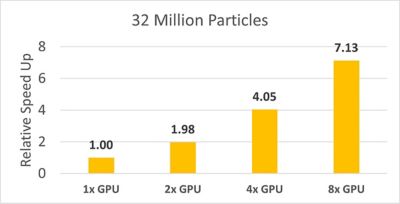
粒子数が3,200万個のケースでの相対的な高速化
粒子数が3,200万個のケースを実行するためにソルバーが使用したGPUメモリの合計は90GB未満でした。つまり、Rockyは実形状粒子の数が2億個を超える同様のケースも処理できることになります。
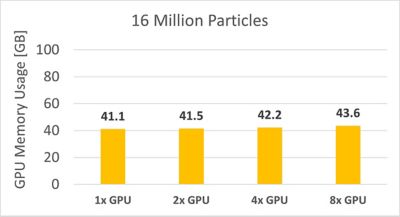
粒子数が1,600万個のケースでのGPUメモリの合計使用量
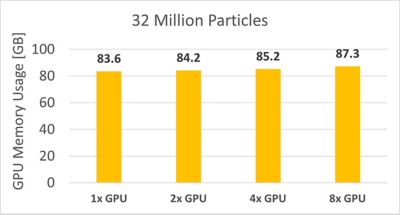
粒子数が3,200万個のケースでのGPUメモリの合計使用量
RockyのマルチGPUソルバーによる結果の最適化
マルチGPU処理能力は、エンジニアリング分野における物理シミュレーションの進化を促進する重要な要素です。
ここで紹介した回転ミルのテスト結果からも、RockyがNVIDIA H100 GPUに対応し、非常に優れたパフォーマンスを発揮することが確認できます。さらに、Rockyはメモリ消費量が少ないため、実形状粒子が2億個を超える巨大なケースにも対応可能です。
RockyのマルチGPUソルバーは、計算能力を集約することで、メモリの制限を克服し、パフォーマンスの大幅な向上を実現します。Rockyは、粒子シミュレーションを高速化し、数千万個の粒子を含む大規模シミュレーションを容易にすることができます。
新しいハードウェアに投資する際のガイドラインと推奨事項については、GPU購入ガイドFAQをご確認ください。
Rockyの詳細については、 当社までお問い合わせください。



Advantageブログ
Ansys Advantageブログでは、専門家が投稿した記事を公開しています。Ansysのシミュレーションが未来のテクノロジーにつながるイノベーションをどのように推進しているかについて最新の情報をご覧ください。