-
-
Access Free Student Software
Ansys empowers the next generation of engineers
Students get free access to world-class simulation software.
-
Connect with Ansys Now!
Design your future
Connect with Ansys to explore how simulation can power your next breakthrough.
Free Trials
Products & Services
Learn
About
Back
Products & Services
Back
Learn
Ansys empowers the next generation of engineers
Students get free access to world-class simulation software.
Back
About
Design your future
Connect with Ansys to explore how simulation can power your next breakthrough.
Free Trials
ANSYS BLOG
March 16, 2022
Simulation Speed vs. Accuracy: AI and GPUs Tip the Balance
There has always been a tradeoff between speed and accuracy, but when it comes to simulation, the use of artificial intelligence/machine learning (AI/ML), combined with graphics processing units (GPUs) are tipping the balance to provide the best of both worlds: rapid innovation and higher confidence. By augmenting simulation methods with AI/ML, we have seen a 40x increase in speed on some applications, and that’s just the beginning.
Simulation is used to analyze increasingly complex multiphysics and system-level phenomena across sectors, including challenges in next-generation products that are advancing electrification, autonomy, 5G, and personalized medicine. It enables our customers to solve problems that were once unsolvable and embrace virtual prototyping, which helps save time and money while increasing quality. However, even though simulation is many times faster than physical testing and prototyping, the market demands even faster innovation, which Ansys has consistently delivered over the past 50+ yefiars.
At NVIDIA GTC, a global AI conference which takes place March 21-24, I will explain how Ansys simulation solutions make use of AI/ML and NVIDIA GPUs to enhance customer productivity, augment existing methods of accelerating simulation runs, enhance engineering design, and provide greater business intelligence insights. Here is a sneak peek at my presentation. By the way, all of the machine learning algorithms I mention below run on the NVIDIA A100 Tensor Core GPU and leverage the ML software stack.
Combining AI and Simulation for Fluid Flows
When you are solving large flow problems with Navier-Stokes equations, it’s complicated to solve for large regions via finite-element or finite-volume methods. You can increase the speed by focusing on small patches of the whole, then learning how those patches connect together to understand the larger regions. That’s where ML comes in. We can create an algorithm to take a single, small solution patch and move that across different regions to solve the larger flow model.
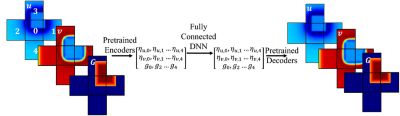
Using this steady-state flow solver as a base, we can then extend it to be a transient ML solver using the same method of focusing on small regions to speed up the solution, which enables us to predict how the flow will vary over time. So, we have our methodology for ML-based steady-state and transient flow solutions. Now, we need to train it.
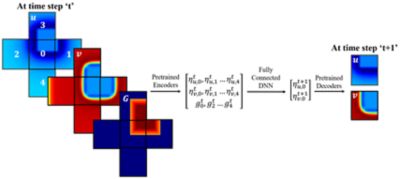
What we’ve done is taken the ML-based flow solver and integrated it with our Ansys Fluent solver so that it is solver-in-the loop. In essence, this enables massive training of data-driven neural networks for a variety of fluid variables.
Some initial results of this ML integration with Fluent on both fluid flow through a pipe and external aerodynamics for a car show a 30-40x faster time to solution using a single CPU. The power of GPUs can provide additional computational speed increases of 5-7x with the potential for scaling up using distributed GPU architectures. GPUs provide a huge potential for simulation speedups using ML-based methods.
Turbulence Model Tuning with AI-ML
Another example of combining ML and simulation is turbulence modeling. The most accurate solver for turbulence is the direct numerical solution (DNS), but that takes a tremendous amount of time, so people use an approximation called large-eddy simulation (LES), which is faster than DNS and still quite accurate. An even faster approximation is Reynolds-average Navier-Stokes (RANS) equations, which is what Fluent uses. RANS equations are not as accurate as LES, so we use generalized k-omega (GEKO) models to get to the accuracy levels of LES while taking advantage of the speed benefits of RANS. However, identifying the GEKO parameters requires the specialized knowledge of a simulation expert. This is where we are applying ML.
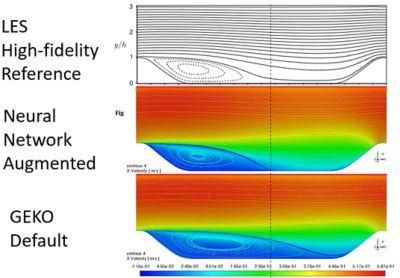
Using ML-based methods, we tune the GEKO parameters automatically instead of manually to get to the accuracy of the LES model.
Find the Best Place for Fine Meshes
Another example of using ML to find the critical places to focus on to accelerate simulation can be found in the electronics field. When simulating electronic chip packages consisting of integrated circuits (ICs) on printed circuit boards (PCBs) or stacked as 3DICs, simulating their thermal properties at the most accurate level can take a very long time. Typically, people speed this up by using adaptive meshing techniques. The time savings are significant. On a 10x10 chip-thermal method simulation, the run time can be reduced from 4.5 hours to 33 minutes using adaptive fine meshing.
You can think of a mesh as a grid of information used to simulate a particular phenomenon. A finer mesh contains more information and takes longer to solve, but is more accurate. Ideally, you would only use finer meshes where they are needed most on chip “hot spots,” and coarser meshes everywhere else to obtain both fast and accurate results. Using ML, we are able to automate the detection of chip hot spots to apply fine meshes where they are needed by predicting the temperature decay curves.
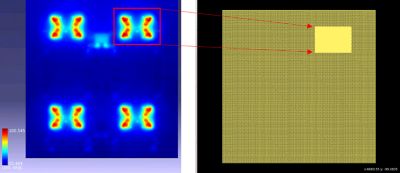
If you integrate those two concepts—adaptive meshing and automated hotspot detection—you can save significant time. For example, on a large 16mmx16mm chip, even a 200x200-micron coarse mesh takes 17 minutes to run. Using the ML-based adaptive meshing to place fine, 10x10-micron meshes where they are needed, it runs in 2m 40s. It provides both accuracy and speed.
To learn more, read the article, "How Artificial Intelligence, Machine Learning, and Simulation Work Together."