Synopsys and Ansys power the future of innovation—connecting silicon to systems.
-
-
Access Free Student Software
Ansys empowers the next generation of engineers
Students get free access to world-class simulation software.
-
Connect with Ansys Now!
Design your future
Connect with Ansys to explore how simulation can power your next breakthrough.
Free Trials
Products & Services
Learn
About
Back
Products & Services
Back
Learn
Ansys empowers the next generation of engineers
Students get free access to world-class simulation software.
Back
About
Design your future
Connect with Ansys to explore how simulation can power your next breakthrough.
Free Trials

Structural simulation workloads are becoming increasingly demanding. As models grow in size and complexity — with nonlinear material behavior, contact interactions, and coupled physics — traditional compute resources often become the limiting factor. Engineers face long solve times, memory bottlenecks, and convergence issues that directly impact project timelines and design iteration cycles.
Ansys Mechanical R2 2025 introduced several high-performance computing (HPC) and solver improvements designed to overcome these bottlenecks. For instance, support for thermal analyses in the mixed solver has been added in 2025 R2, and the PCG iterative solver now consumes a lot less memory, particularly at high core counts.
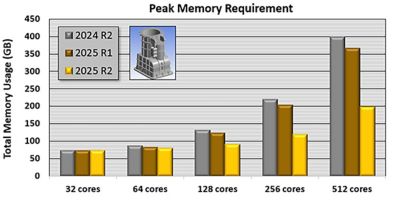
Peak memory reduction of PCG solver from Ansys 2024 R2 to 2025 R2 across core counts (V24iter-3 benchmark, 25M DOF, modal analysis using the PCG Lanczos eigensolver requesting 10 mode shapes). Tests were run on a Linux cluster with compute nodes featuring dual Intel Xeon Gold 6448H CPUs and 1024 GB RAM.
By providing hybrid parallelism and the mixed solver architecture that was introduced in 2025 R1, Ansys is enabling users to solve larger models faster and more efficiently while reducing memory usage and expanding hardware compatibility.
Hybrid Parallelism Enhances CPU Resource Utilization
Hybrid parallelism in Mechanical software integrates shared memory parallelism (SMP) and distributed memory parallelism (DMP), enabling users to fine-tune their simulation jobs based on available hardware. While SMP threads execute on the same node, DMP distributes processes across multiple nodes using Message Passing Interface (MPI). In hybrid mode, engineers can set the number of MPI processes and threads per process (e.g., 16 MPI processes with NT=2 on a 32-core node) to balance memory usage and computational throughput.
This configuration is especially beneficial for large-scale finite element analysis (FEA) models. For example, simulations involving 100+ million degrees of freedom (DOF) can run entirely in memory, without paging, by optimizing the thread/process split. The hybrid setup reduces the per-process memory footprint and improves scalability when running across multiple nodes.

Hybrid parallelism improves scalability and reduces memory demands in large-scale finite element analysis (FEA) simulations. This example with an engine block model shows how increasing threads per process (NT=2, NT=4) reduces memory usage, enabling more efficient CPU core utilization.
In 2025 R2, solver configuration remains accessible via the Mechanical interface or directly through Mechanical APDL (MAPDL) using advanced launch settings. This makes it easier for experienced users to tune performance across hardware topologies.
Mixed Solver Architecture Improves Simulation Speed and Efficiency
The mixed solver combines sparse direct and PCG iterative solvers into a unified, hybrid computational path that spans both CPU and GPU. This architecture dynamically balances solver strategies based on the characteristics of the model and the hardware configuration. It uses double- and single-precision arithmetic across both CPUs and GPUs for improved performance and memory efficiency.
This approach is particularly effective for nonlinear static and transient simulations involving plasticity, creep, geometric nonlinearity, and large contact sets. And these benefits are not limited to high-end GPUs — in recent tests, the cost-effective NVIDIA RTX A6000 Ada workstation GPU achieved performance comparable to an H100 data center GPU on a 4M DOF engine block model. This underscores how the mixed solver not only accelerates simulations but also broadens hardware accessibility for engineers using workstation-class hardware.

Mixed solver performance comparison for a nonlinear static analysis of an engine block model (~4.1 million DOF) involving plasticity, geometric nonlinearities, and contact. Tests were performed using Ansys Mechanical 2025 R1 with 16 CPU cores (DMP) and 1 GPU on a Linux server (2× Intel Xeon Gold 6342, 1 TB RAM, SSD, RHEL 8.9) equipped with either an NVIDIA H100 NVL or RTX A6000 Ada card.
Quantifying Return on Investment From Simulation Acceleration
In addition to performance benefits, these solver and HPC improvements also translate to measurable financial gains. A recent third-party study conducted by Hyperion Research across 71 Ansys customer projects showed that:
- Every $1 spent on HPC infrastructure returned $152 in revenue.
- Each dollar also contributed $35 in direct cost savings or profit.
A further breakdown can be found in the table below:
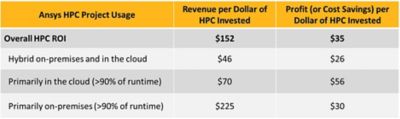
These figures underscore the business case for investing in scalable simulation resources, whether on-premises or in the cloud.
Flexible HPC Deployment Options Help Match Evolving Needs
Ansys supports a wide range of HPC deployment paths to meet users wherever they are in their simulation journey. For many, the journey starts modestly on premises — with laptops, desktops, or turnkey HPC systems — and expands as simulation complexity and user demand grow.
For added flexibility and scalability, Ansys offers multiple cloud HPC solutions:
- The Ansys Cloud Burst Compute tool provides secure, on-demand HPC with integrated cloud-connected simulation tools.
- The Ansys Access on Microsoft Azure cloud engineering solution lets users run simulations using their own licenses via a flexible subscription through the Azure Marketplace.
- The Ansys Gateway powered by AWS cloud engineering solution enables fully customizable cloud-based environments accessible from any browser and supports both Ansys and third-party tools.
Whether on-premises or in the cloud, these options ensure users can scale performance as simulation demands grow, without compromising usability or control.
Best Practices To Maximize HPC Performance
To fully exploit these advancements, end users should follow a few key technical best practices:
- Evaluate the PCG, sparse, and mixed solvers based on problem size, contact conditions, and memory availability.
- Use hybrid configurations with thread counts optimized to minimize NUMA effects and maximize memory bandwidth utilization.
- Enable automatic contact splitting to improve convergence and reduce solver iterations in contact-dominated models.
- Ensure memory channels are fully populated. Use SSDs or RAID 0 storage for fast read/write and leverage GPU acceleration where supported.
- Monitor element load balance ratio and solver statistics to identify inefficiencies and fine-tune step sizes, tolerances, and decomposition parameters.
Download the White Paper To Learn More
Whether you're scaling up nonlinear simulations or trying to reduce turnaround time for large assemblies, the latest white paper, “Best Practices and HPC Strategies for Ansys Mechanical,” provides actionable guidance and benchmark data to help you get the most from Mechanical structural FEA software and your HPC investment.




The Advantage Blog
The Ansys Advantage blog, featuring contributions from Ansys and other technology experts, keeps you updated on how Ansys simulation is powering innovation that drives human advancement.