-
-
Kostenlose Software für Studierende
Ansys unterstützt die nächste Generation von Ingenieur*innen
Studenten erhalten kostenlosen Zugang zu erstklassiger Simulationssoftware.
-
Verbinden Sie sich jetzt mit Ansys!
Gestalten Sie Ihre Zukunft
Stellen Sie eine Verbindung mit Ansys her, um zu erfahren, wie Simulation Ihren nächsten Durchbruch vorantreiben kann.
Kostenlose Demoversionen
Produkte & Dienstleistungen
Lernportal
Über das Unternehmen
Back
Produkte & Dienstleistungen
Back
Lernportal
Ansys unterstützt die nächste Generation von Ingenieur*innen
Studenten erhalten kostenlosen Zugang zu erstklassiger Simulationssoftware.
Back
Über das Unternehmen
Gestalten Sie Ihre Zukunft
Stellen Sie eine Verbindung mit Ansys her, um zu erfahren, wie Simulation Ihren nächsten Durchbruch vorantreiben kann.
Kostenlose Demoversionen
ANSYS BLOG
May 11, 2022
Unleashing the Full Power of GPUs for Ansys Fluent, Part 1
Your commute home from work, the flight from New York to London, the old coffee maker at the office that your company still won’t upgrade ... Just like computational fluid dynamics (CFD) simulations, all these things would benefit from being sped up.
Over the years, one of the key enablers to accelerate CFD simulations has been high-performance computing (HPC), and in more recent years that has expanded to graphical processing units (GPUs).
Leveraging GPUs in the CFD world is not a new concept. GPUs have been used as CFD accelerators for quite some time (including in Ansys Fluent since 2014). However, the local acceleration you get is problem dependent. In the end, the portion of the code not optimized for GPUs will throttle your overall speedup. That is why we want to show you the potential that GPUs have when CFD simulations are run natively on multiple GPUs.
This is the first installment of our blog series, "Unleashing the Full Power of GPUs for Ansys Fluent," which will demonstrate how GPUs can help reduce simulation time, hardware costs, and power consumption. In this first installment we will cover a few laminar and turbulent flow problems. As the series progresses, so will the physics modeling capabilities discussed. Please access Part 2 of this blogs here.
32X Speed Up for Automotive External Aerodynamics
For our first example, let’s look at automotive external aerodynamics simulations, which can become very large very quickly — commonly in excess of 300 million cells. Running a simulation of this size would require thousands of cores and days (sometimes even weeks) of compute time. What if there was a way to reduce the simulation time from weeks to days or days to hours, while also significantly reducing the power consumption? Spoiler alert: there is, and that is by running these simulations completely on GPUs.
Sustainability is a key concern in the automotive industry, and government agencies around the world are putting strict regulations in place. Some areas that automotive companies have been evaluating to meet or exceed these regulations include:
- Improving aerodynamics
- Reducing emissions
- Using alternative fuels
- Developing hybrid and electric powertrain options
But sustainability efforts should not be limited to the operation of the end product (in this case a car) – such efforts should extend to the design process of the product as well. This includes simulation, and we at Ansys want to reduce the amount of power consumed during simulations.

Automotive external aerodynamics simulations can be sped up by running completely on GPUs
For the simulation shown, we ran the benchmark DrivAer model on different CPU and GPU configurations using Fluent and compared the performance. Our results show that a single NVIDIA A100 GPU achieved more than 5X greater performance than a cluster with 80 Intel® Xeon® Platinum 8380 Cores. When scaling up to 8 NVIDIA A100 GPUs, the simulation can be sped up by more than 30X.
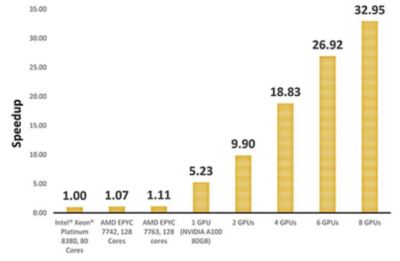
Speedup of an automotive external aerodynamics simulation when leveraging GPUs
Getting results in less time makes our customers more efficient, but it doesn’t stop there: We can also reduce their electric bill (and help the planet!) with a major reduction in the power required to run such simulations.
We looked at the power consumption of a CPU cluster with 1024 Intel® Xeon® Gold 6242 cores and noted a power consumption of 9600 W. When comparing to the power consumption of a 6 x NVIDIA® V100 GPU server providing the same performance, that power consumption was reduced by a factor of four down to 2400 W.
These benchmark results demonstrate that companies opting for a 6 x NVIDIA® V100 GPU server can reduce their power consumption by 4X compared to an equivalent HPC cluster, and this doesn’t even consider the reduced cooling costs to keep the server room cool.
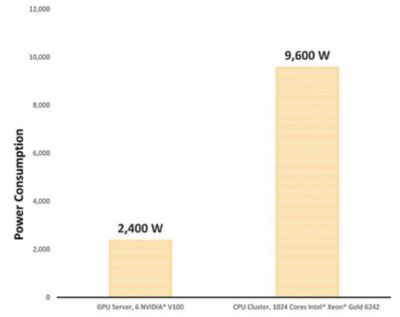
Power consumption reduction when using a GPU server
Running your simulations on a native GPU solver can have a massive and immediate impact, in both your company’s sustainability efforts and reducing the time you spend waiting for results. And not just any results — these are results you can trust. Over the past 40+ years, Fluent has been extensively validated across a wide range of applications and is known for its industry leading accuracy. Both the CPU and multi-GPU solver available within Fluent are built on the same discretization and numerical methods, providing users virtually identical results.
The two canonical cases below are well established CFD validations that simulate the fundamentals from the laminar and turbulent regimes. Both cases detail the accuracy a user will get when solved natively on GPUs.
Laminar Flow Over a Sphere
Literature abounds with experimental and numerical studies of flow over a sphere, serving as a basic benchmark for external aerodynamics validation. For this first test, we chose laminar flow conditions where the Reynolds number is equal to 100 and the fluid is expected to go around the sphere and form time-invariant vortex structures behind the cylinder. Drag correlations proposed in the literature are used to compare CFD results with experimental data.
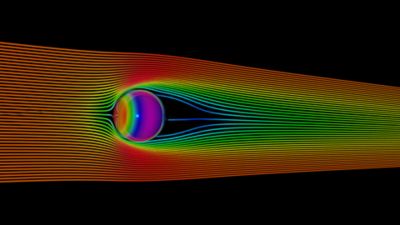
Velocity streamlines and pressure distribution for laminar flow over a sphere benchmark
As shown in Table 1, the native GPU implementation computes the drag coefficient very accurately, with an error percentage of only -0.252%.

Table 1. Drag coefficient (Cd) comparison
Backward Facing Step
The backward-facing step is a canonical problem used to test turbulence model implementation. The seemingly simple configuration is rich in the physics it exhibits. For this test, we recreated the experimental set up by Vogel and Eaton2 with a velocity inlet of 2.3176 m/s. CFD codes are put to the test by comparing velocity profiles at different planes along the length of the channel with published experimental data.

Velocity vectors for the backward-facing step
When solved on CPUs, Fluent shows good validation with experimental results3,4. Solving this same problem with the native multi-GPU solver provides users with virtually identical results, as shown below, because both the CPU and GPU solvers available in Fluent are built on the same discretization and numerical methods.
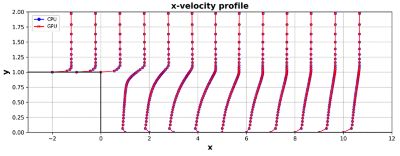
Velocity profile results for the backward facing step when solved on CPUs and GPUs
This native multi-GPU implementation of an unstructured, finite volume Navier-Stokes solver that accepts all mesh types is truly novel and sets a new standard for CFD, making no compromise on accuracy. Interested in seeing the massive speedups you can get from tapping into the potential of GPUs for your problem? Contact us now.
References
- Turton, R.; and Levenspiel, O., A short note on the drag correlation for spheres, Powder Technol., 47, 83-86, 1986
- Vogel J.C., and Eaton, J. K. (1985) Combined heat transfer and fluid dynamic measurements downstream of a backwards-facing step. J. Heat Transfer 107, 922-929.
- Smirnov, Evgueni & Smirnovsky, Alexander & Shchur, Nikolai & Zaitsev, Dmitri & Smirnov, P. (2018). Comparison of RANS and IDDES solutions for turbulent flow and heat transfer past a backward-facing step. Heat and Mass Transfer. 54. 10.1007/s00231-017-2207-0
- Banait H., Bais A., Khondekar K., Choudhary R., Bhambere M.B. (2020). Numerical Simulation of Fluid Flow over a Modified Backward Facing Step using CFD. International Research Journal of Engineering and Technology. Volume 7, Issue 9