Synopsys and Ansys power the future of innovation—connecting silicon to systems.

在Gefion超级计算机上使用NVIDIA CUDA-Q,Ansys计算流体力学仿真规模成功扩展到了39个量子比特(qubit)。
计算流体力学(CFD)仿真已成为航空航天、汽车、能源以及加工行业不可或缺的技术。随着设计进程的加速以及保真度要求的提高,CFD模型的规模和复杂性不断增加,对更大内存容量、更精细空间分辨率以及更短周转时间的需求也在不断增长。长期以来,Ansys始终致力于应对这些挑战,不仅率先推出了高性能求解器,而且还将高性能计算(HPC)与人工智能(AI)融合,在不影响准确性的情况下,加速收敛,降低计算成本。
Ansys首席技术官办公室积极研究能够加速偏微分方程(PDE)求解的量子算法,由于研究界已有成熟的基准测试案例,该研究的初始重点为CFD领域。我们采用NVIDIA CUDA-Q开源量子开发平台构建量子应用堆栈,如今,这不仅可在无噪声的环境中实现基于GPU的可扩展的算法仿真,而且还能在未来超越噪声中等规模量子(NISQ)时代时,在量子硬件上实现无缝运行。一旦确定算法可扩展至工业规模及复杂度,我们就会进入硬件验证阶段,因为这就是研究的下一个步骤。该迭代过程,可帮助我们逐步收敛到最有效的量子计算方法。
NVIDIA CUDA-Q平台在开发混合量子经典工作流程和GPU加速量子电路仿真方面的灵活性,在帮助我们研究算法如何扩展的过程中发挥了关键作用。
当量子计算遇到CFD
量子算法旨在巧妙利用信息在量子系统中编码时可能的新处理方式。量子系统似乎特别适合计算量极其庞大的CFD仿真,尤其是在以下方面:
高维度:与经典比特不同,量子比特(也叫量子位)可编码随其数量呈指数级扩展的数据。每增加一个量子比特,可寻址数据空间就会增加一倍。通过将整个计算网格(可能包含数十亿个点)表示为量子态振幅,量子计算便可访问更大求解空间。实际上,本博客后面也有演示:我们只用39个量子比特,就解决了涉及680亿个网格点的问题!
并行全局更新:量子计算提供了迭代更新数据的契机,可通过CFD中常用的时间步演变为整体操作,在单次量子电路执行中完成。并且,其无需迭代调用内核,便可同时更新所有网格点。
然而,要将这些特性成功应用于实际的CFD应用,比我们所以为的要复杂得多。这需要构建复杂的算法,不仅要能操控编码在量子比特中的CFD信息,还要能够进行读取。量子晶格玻尔兹曼法(QLBM)就是实现这些目标的一种方法。
何为量子晶格玻尔兹曼法(QLBM)?
在CFD中,标量密度场的传递由对流扩散()方程控制,这是一个典型问题,通常是开发经典数值方法的初始基准。
QLBM是经典晶格玻尔兹曼法的量子原生实现,在这里经过调整,可高效解决量子硬件的流体仿真问题。因为其固有的局部结构化更新规则可以自然地映射到量子电路上,QLBM特别适合量子CFD。QLBM不仅保留了LBM的简洁性和模块化特性,同时还可释放量子计算在数据表示和处理能力上的指数级潜力。
QLBM中的每个时间步均包含四个关键操作:
- 态制备(State Preparation):初始化“网格寄存器”,其振幅将对离散晶格上的标量密度场编码。
- 碰撞(Collision):通过单位算子的线性组合来实现碰撞操作。除网格寄存器中的量子比特外,该步骤还需要辅助量子比特。
- 传输(Streaming):执行受控移位(controlled-shift)算子,根据对流(advection)动力学传播振幅。
- 读出(Readout):测量量子寄存器,重新构建更新的密度分布。
通过这些操作,QLBM能够将整个晶格上的完整时间步更新作为整体、相干的量子操作来完成,而无需像经典显式时间推进方法那样逐点顺序更新。
创记录规模的39量子比特仿真
与NVIDIA合作,Ansys在DCAI的Gefion超级计算机上的183个节点上部署CUDA-Q,成功执行了39个量子比特的QLBM仿真:
- 36个空间量子比特:编码一个218×218的2D网格,大约有680亿个自由度。
- 3个辅助量子比特:支持碰撞与数据流逻辑。
- 平台:使用CUDA-Q编写的算法代码,通过CUDA-Q“cpu”目标平台,进行了本地CPU的小型初步测试。随后,通过“nvidia”目标平台,可轻松扩展到中等规模的本地GPU环境。最后,使用相同的代码,将CUDA-Q的目标平台切换到“mgpu”,在Gefion上进行大规模运行,使用了183个节点,总计1464个GPU。不久的将来,通过使用CUDA-Q支持的各种量子比特类型,同一段代码将在量子处理器(QPU)上运行将成为可行。
大规模AI优化基础架构
上述仿真在一台丹麦AI创新中心(DCAI)运营的AI超级计算机Gefion上运行,该中心的使命是通过提供前沿计算功能,在各领域间为AI加速。Gefion基于NVIDIA DGX SuperPOD架构,在全球500强超级计算机榜单中名列第21位。
Gefion中的高级计算架构可将服务器连接起来,作为一个整体运行,在每个节点上提供3.2Tb/s的连接,这在帮助算法构建并操纵大型量子状态向量的过程中非常有用。使用CUDA-Q框架的nvidia-mgpu目标来生成量子态向量(statevectors),通过将各节点的GPU VRAM汇聚在一起,让科学家无需操心内存管理的细节。
在峰值执行时,仿真使用183个DGX节点,每个节点配备8个H100 GPU,总计1464个GPU,在仿真中提供了大约85.7 PFLOPS(FP64张量运算性能)。计算互连网络由高速的八通道(octo-rail)NVIDIA Quantum-2 InfiniBand网络组成,每个GPU直接连接至计算架构,带宽为400Gb/s,每秒在每个GPU之间传输数十GB的数据。该存储系统使用800Gb/s的连接实现了超过200GB/s的IO500带宽,其中“易写入(easy write)”速度为563 Gb/s,“易读取(easy read)”速度为910Gb/s。
Gefion一直是项目期间并行化计算的理想测试平台,可使分析组件能够顺利地在集群中分布运行。自适应资源分配模型和HPC专家运营团队,使项目能够无缝地发挥硬件的最大性能。
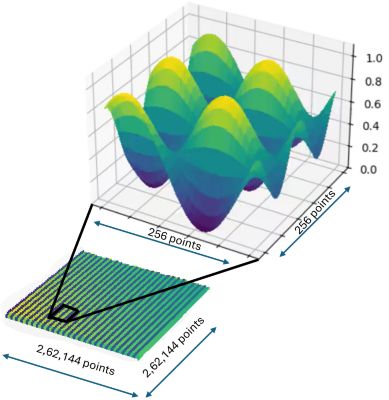
2,62,144 x 2,62,144网格上的2D正弦波均匀平流扩散,使用39个量子比特进行仿真
我们将Ansys深厚的求解器开发专业技术与NVIDIA高性能CUDA-Q平台上量子算法研究的开拓性进展融合,为量子加速流体动力学奠定了坚实基础。随着量子计算技术的发展,这项工作具有重要的前瞻性价值,有助于规划工业级量子CFD发展的系统化路径,以应对未来工程挑战不断增长的计算需求。
如欲了解更多详情,敬请参阅“面向可实现化的量子晶格玻尔兹曼法的算法进展”。



Advantage博客
Ansys Advantage博客(The Advantage Blog)由Ansys专家和其他技术专家撰写,让您随时了解Ansys如何为创新赋能,推动人类踏上伟大征程。